

OpenMP教程
MPI 教程
OpenMP的执行模式采用fork-join模式,什么是fork-join呢?如下图所示:
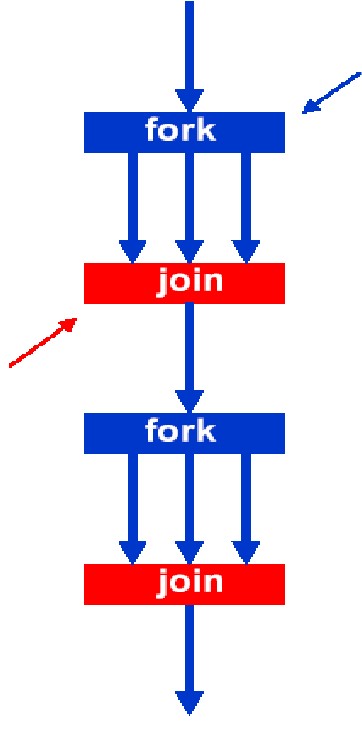
成对的fork和join之间的区域称之为并行域,fork创建新线程,join就是多个线程的汇合。在这个模型中,一开始只有一个主线程——老大,然后主线程遇到相关的命令就会创建多个线程——小弟。
二、openMP语句模式:
OpenMP通过编译指导命令来并行化,什么是编译指导命令?简单来说就是我们平常写的#开头的语句,通过程序中插入的这些编译指导命令,计算机就会完成并行计算的工作。在C/C++程序中,OpenMP的所有的编译指导命令都是以#pragma omp开始的,后面跟具体的功能指导命令,命令形式如下:
三、简单的语句——开始并行!
前文讲到了openMP的语句方式,现在先来解锁一个最为简单也最为频繁的指令 parallel
xxxxxxxxxxusing namespace std;int main(){ { cout << "Hello, world!" << endl; }}parallel制导命令表示接下来由花括号括起来的区域将创建多个线程并行执行。可以用num_threads子句来控制线程的个数,如下:
xxxxxxxxxxusing namespace std;int main(){ { cout << "Hello, world!" << endl; }}还可以用一个函数:
xxxxxxxxxxusing namespace std;int main(){ omp_set_num_threads(2); { cout << "Hello, world!" << endl; }}好了,现在你已经懂了如何让特定的程序区域并行起来,接下来将解锁一个常用的制导命令 for,直接将你的for循环体提升n倍!在并行域里面用以下命令,在这条语句之后的一个for循环语句中每一个要循环的任务将被分配给不同的线程去执行。
xxxxxxxxxx例如:
xxxxxxxxxxusing namespace std;int main(){ omp_set_num_threads(2); { for(int i=0;i<4;i++) cout << omp_get_thread_num() << endl; }}也可以直接把for写在parallel后面
xxxxxxxxxx for(int i = 0, i < n;i++) //一定要加int否则i为全局变量,所有线程同时对i进行修改
四、for循环语句的分配模式
在以上的任务中,各个线程自动分配到要执行的任务标号,没有对任务做一些进一步的调度,接下来介绍的字句将会对for循环任务的调度做更细致一些的规定。
用schedule子句进行for循环任务调度的管理
schedule子句形式
xxxxxxxxxxschedule(type, size)type参数有四种:1.static, 2.dynamic, 3.guided, 4.runtime
size参数是整形数据:表示循环迭代次数划分的单位。
1.static参数
静态调度,不用size参数时分配给每个程序的都是n/t次连续迭代,n为迭代次数,t为并行的线程数目。
xxxxxxxxxxusing namespace std;int main(){ omp_set_num_threads(2); for(int i=0;i<8;i++) cout << omp_get_thread_num() << endl;}使用size参数,表示每次分配给线程size次的连续迭代。
2.dynamic参数
动态调度模式是先到先得的方式进行任务分配,不用size参数的时候,先把任务干完的线程先取下一个任务,以此类推,而不是一开始就分配固定的任务数。使用size参数的时候,分配的任务以size为单位,一次性分配size个。虽然很智能,在任务难度不均衡的时候适合用dynamic,否则会引起过多的任务动态申请的开销。
3.guided参数
刚开始每个线程会分配到比较大的迭代块,后来分配到的迭代块逐渐递减,没有指定size就会降到1,否则降到size。
4.runtime
基本不会用到,需要了解的可以自行了解。
五、sections制导指令
用sections把不同的区域交给不同的线程去执行
用法:
xxxxxxxxxx#include<omp.h>#include<iostream>using namespace std;int main(){ omp_set_num_threads(3);#pragma omp parallel sections {#pragma omp section { cout <<omp_get_thread_num(); }#pragma omp section { cout << omp_get_thread_num(); }#pragma omp section { cout << omp_get_thread_num(); } }}可以看出这时候三个线程分为三部分并发执行每一个section区域。
六、single制导指令
single制导指令所包含的代码段只有一个线程执行,别的线程跳过该代码,如果没有nowait子句,那么其他线程将会在single制导指令结束的隐式同步点等待。有nowait子句其他线程将跳过等待往下执行。
xxxxxxxxxxint main(){ omp_set_num_threads(4);#pragma omp parallel {#pragma omp single { cout << "single thread=" << omp_get_thread_num()<<endl; } cout << omp_get_thread_num() << endl; } }执行结果
可以看出,在隐式同步点已经同步。这个代码和运行结果可能不太明显,大家懂这个意思就好了。single由一个线程进行执行,然后其它线程等它执行完然后汇合一起往下执行。
添加上nowait子句就不会在隐式点同步了。
线程被包含在线程组中,线程组中的线程数目可以用运行时函数调用omp_get_num_threads来得到
每个线程都有一个组内的线程号(从0开始),线程号为0的线程作为线程组的组长,它可以进行一些特别的操作。线程的线程号可以由运行时函数调用omp_get_thread_num来得到